Note
Go to the end to download the full example code.
Variable Importance on diabetes dataset#
Variable Importance estimates the influence of a given input variable to the prediction made by a model. To assess variable importance in a prediction problem, Breiman[1] introduced the permutation approach where the values are shuffled for one variable/column at a time. This permutation breaks the relationship between the variable of interest and the outcome. Following, the loss score is checked before and after this substitution for any significant drop in the performance which reflects the significance of this variable to predict the outcome. This ease-to-use solution is demonstrated, in the work by Strobl et al.[2], to be affected by the degree of correlation between the variables, thus biased towards truly non-significant variables highly correlated with the significant ones and creating fake significant variables. They introduced a solution for the Random Forest estimator based on conditional sampling by performing sub-groups permutation when bisecting the space using the conditioning variables of the buiding process. However, this solution is exclusive to the Random Forest and is costly with high-dimensional settings. CHAMMA et al.[3] introduced a new model-agnostic solution to bypass the limitations of the permutation approach under the use of the conditional schemes. The variable of interest does contain two types of information: 1) the relationship with the remaining variables and 2) the relationship with the outcome. The standard permutation, while breaking the relationship with the outcome, is also destroying the dependency with the remaining variables. Therefore, instead of directly permuting the variable of interest, the variable of interest is predicted by the remaining variables and the residuals of this prediction are permuted before reconstructing the new version of the variable. This solution preserves the dependency with the remaining variables.
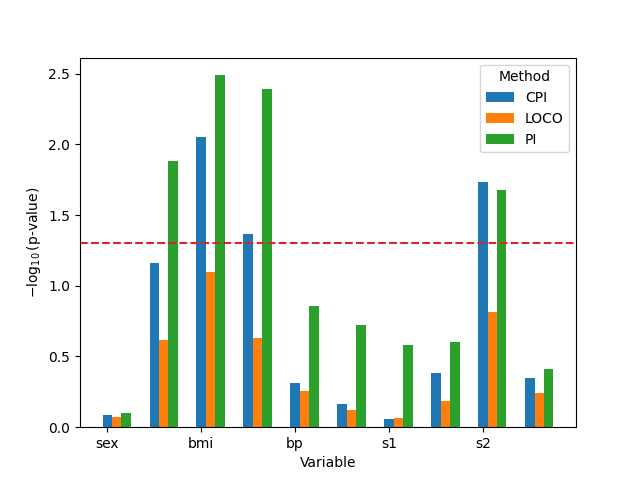
In this example, we compare both the standard permutation and its conditional variant approaches for variable importance on the diabetes dataset for the single-level case. The aim is to see if integrating the new statistically-controlled solution has an impact on the results.
References#
Imports needed for this script#
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from scipy.stats import norm
from sklearn.base import clone
from sklearn.datasets import load_diabetes
from sklearn.linear_model import LogisticRegressionCV, RidgeCV
from sklearn.metrics import r2_score, root_mean_squared_error
from sklearn.model_selection import KFold
from hidimstat import CPI, LOCO, PermutationImportance
Load the diabetes dataset#
diabetes = load_diabetes()
X, y = diabetes.data, diabetes.target
# Encode sex as binary
X[:, 1] = (X[:, 1] > 0.0).astype(int)
Fit a baseline model on the diabetes dataset#
We use a Ridge regression model with a 10-fold cross-validation to fit the diabetes dataset.
n_folds = 5
regressor = RidgeCV(alphas=np.logspace(-3, 3, 10))
regressor_list = [clone(regressor) for _ in range(n_folds)]
kf = KFold(n_splits=n_folds, shuffle=True, random_state=0)
for i, (train_index, test_index) in enumerate(kf.split(X)):
regressor_list[i].fit(X[train_index], y[train_index])
score = r2_score(
y_true=y[test_index], y_pred=regressor_list[i].predict(X[test_index])
)
mse = root_mean_squared_error(
y_true=y[test_index], y_pred=regressor_list[i].predict(X[test_index])
)
print(f"Fold {i}: {score}")
print(f"Fold {i}: {mse}")
Fold 0: 0.3308347338292018
Fold 0: 58.578414587143264
Fold 1: 0.46121055962206037
Fold 1: 53.69203761571753
Fold 2: 0.532580377477482
Fold 2: 54.7109767813034
Fold 3: 0.5064809104496388
Fold 3: 54.27241662381731
Fold 4: 0.5979653259032667
Fold 4: 52.28738181690639
Fit a baselien model on the diabetes dataset#
We use a Ridge regression model with a 10-fold cross-validation to fit the diabetes dataset.
n_folds = 10
regressor = RidgeCV(alphas=np.logspace(-3, 3, 10))
regressor_list = [clone(regressor) for _ in range(n_folds)]
kf = KFold(n_splits=n_folds, shuffle=True, random_state=0)
for i, (train_index, test_index) in enumerate(kf.split(X)):
regressor_list[i].fit(X[train_index], y[train_index])
score = r2_score(
y_true=y[test_index], y_pred=regressor_list[i].predict(X[test_index])
)
mse = root_mean_squared_error(
y_true=y[test_index], y_pred=regressor_list[i].predict(X[test_index])
)
print(f"Fold {i}: {score}")
print(f"Fold {i}: {mse}")
Fold 0: 0.34890711975297883
Fold 0: 56.14418259464154
Fold 1: 0.2721892039082885
Fold 1: 61.353949860279265
Fold 2: 0.5366616548610812
Fold 2: 49.06762118785067
Fold 3: 0.369613881109925
Fold 3: 59.01755532551764
Fold 4: 0.5855653971685906
Fold 4: 51.49494754541356
Fold 5: 0.4624358145573261
Fold 5: 58.313463230719215
Fold 6: 0.5237829173242109
Fold 6: 51.342031718187556
Fold 7: 0.48524399114935435
Fold 7: 56.84140735040936
Fold 8: 0.6653054560599736
Fold 8: 47.26185304374659
Fold 9: 0.5514651857121984
Fold 9: 55.7232074733178
Measure the importance of variables using the CPI method#
cpi_importance_list = []
for i, (train_index, test_index) in enumerate(kf.split(X)):
print(f"Fold {i}")
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
cpi = CPI(
estimator=regressor_list[i],
imputation_model_continuous=RidgeCV(alphas=np.logspace(-3, 3, 10)),
imputation_model_categorical=LogisticRegressionCV(Cs=np.logspace(-2, 2, 10)),
# covariate_estimator=HistGradientBoostingRegressor(random_state=0,),
n_permutations=50,
random_state=0,
n_jobs=4,
)
cpi.fit(X_train, y_train)
importance = cpi.score(X_test, y_test)
cpi_importance_list.append(importance)
Fold 0
Fold 1
Fold 2
Fold 3
Fold 4
Fold 5
Fold 6
Fold 7
Fold 8
Fold 9
Measure the importance of variables using the LOCO method#
loco_importance_list = []
for i, (train_index, test_index) in enumerate(kf.split(X)):
print(f"Fold {i}")
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
loco = LOCO(
estimator=regressor_list[i],
n_jobs=4,
)
loco.fit(X_train, y_train)
importance = loco.score(X_test, y_test)
loco_importance_list.append(importance)
Fold 0
Fold 1
Fold 2
Fold 3
Fold 4
Fold 5
Fold 6
Fold 7
Fold 8
Fold 9
Measure the importance of variables using the permutation method#
pi_importance_list = []
for i, (train_index, test_index) in enumerate(kf.split(X)):
print(f"Fold {i}")
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
pi = PermutationImportance(
estimator=regressor_list[i],
n_permutations=50,
random_state=0,
n_jobs=4,
)
pi.fit(X_train, y_train)
importance = pi.score(X_test, y_test)
pi_importance_list.append(importance)
Fold 0
Fold 1
Fold 2
Fold 3
Fold 4
Fold 5
Fold 6
Fold 7
Fold 8
Fold 9
Define a function to compute the p-value from importance values#
Analyze the results#
cpi_vim_arr = np.array([x["importance"] for x in cpi_importance_list]) / 2
cpi_pval = compute_pval(cpi_vim_arr)
vim = [
pd.DataFrame(
{
"var": np.arange(cpi_vim_arr.shape[1]),
"importance": x["importance"],
"fold": i,
"pval": cpi_pval,
"method": "CPI",
}
)
for x in cpi_importance_list
]
loco_vim_arr = np.array([x["importance"] for x in loco_importance_list])
loco_pval = compute_pval(loco_vim_arr)
vim += [
pd.DataFrame(
{
"var": np.arange(loco_vim_arr.shape[1]),
"importance": x["importance"],
"fold": i,
"pval": loco_pval,
"method": "LOCO",
}
)
for x in loco_importance_list
]
pi_vim_arr = np.array([x["importance"] for x in pi_importance_list])
pi_pval = compute_pval(pi_vim_arr)
vim += [
pd.DataFrame(
{
"var": np.arange(pi_vim_arr.shape[1]),
"importance": x["importance"],
"fold": i,
"pval": pi_pval,
"method": "PI",
}
)
for x in pi_importance_list
]
fig, ax = plt.subplots()
df_plot = pd.concat(vim)
df_plot["pval"] = -np.log10(df_plot["pval"])
methods = df_plot["method"].unique()
colors = plt.cm.get_cmap("tab10", 10)
for i, method in enumerate(methods):
subset = df_plot[df_plot["method"] == method]
ax.bar(
subset["var"] + i * 0.2,
subset["pval"],
width=0.2,
label=method,
color=colors(i),
)
ax.legend(title="Method")
ax.set_ylabel(r"$-\log_{10}(\text{p-value})$")
ax.axhline(-np.log10(0.05), color="tab:red", ls="--")
ax.set_xlabel("Variable")
ax.set_xticklabels(diabetes.feature_names)
plt.show()
/home/runner/work/hidimstat/hidimstat/examples/plot_diabetes_variable_importance_example.py:239: MatplotlibDeprecationWarning: The get_cmap function was deprecated in Matplotlib 3.7 and will be removed in 3.11. Use ``matplotlib.colormaps[name]`` or ``matplotlib.colormaps.get_cmap()`` or ``pyplot.get_cmap()`` instead.
colors = plt.cm.get_cmap("tab10", 10)
/home/runner/work/hidimstat/hidimstat/examples/plot_diabetes_variable_importance_example.py:255: UserWarning: set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
ax.set_xticklabels(diabetes.feature_names)
Total running time of the script: (0 minutes 6.313 seconds)
Estimated memory usage: 196 MB